Special Report
Imputation is a powerful statistical method that is distinct from the predictive modelling techniques more commonly used in drug discovery.
Imputation uses the known data explicitly to reconstruct the missing elements allowing assay–assay correlations and thereby gains more value from the investment in experimental measurements.
One immediate and obvious advantage with imputation is the filling of the entire data matrix, which can provide as much as 100-times the original data.
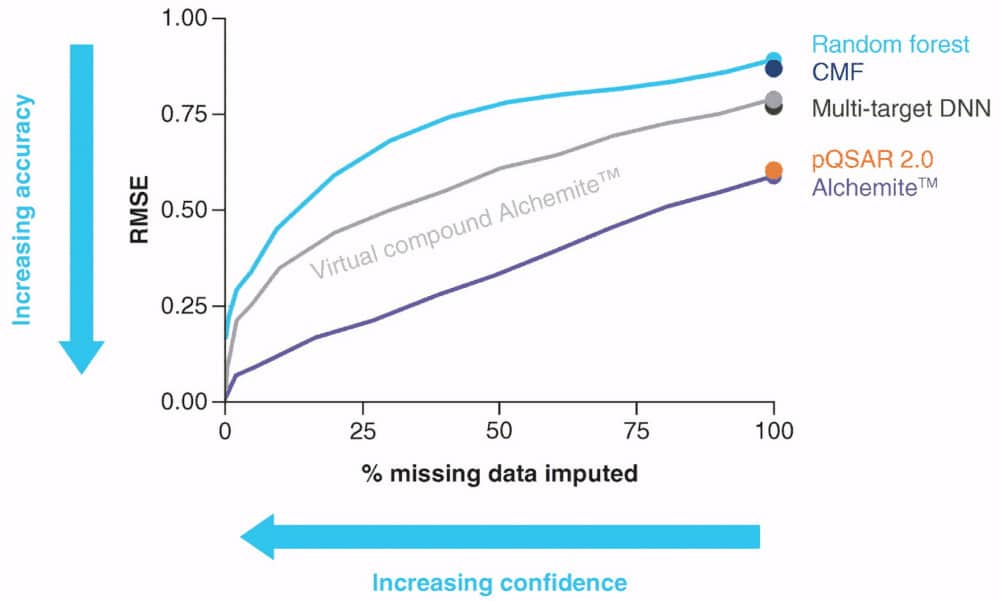
Imputation is a powerful statistical method that is distinct from the predictive modelling techniques more commonly used in drug discovery. Imputation uses sparse experimental data in an incomplete dataset to predict missing values by leveraging correlations between experimental assays. This contrasts with quantitative structure–activity relationship methods that use only descriptor – assay correlations. We summarize three recent imputation strategies – heterogeneous deep imputation, assay profile methods and matrix factorization – and compare these with quantitative structure–activity relationship methods, including deep learning, in drug discovery settings. We comment on the value added by imputation methods when used in an ongoing project and find that imputation produces stronger models, earlier in the project, over activity and absorption, distribution, metabolism and elimination end points.
Publication details
Publication: Future Drug Discovery
Title: Imputation versus prediction: applications in machine learning for drug discovery
Authors: Benedict W.J. Irwin, Samar Mahmoud, Thomas M. Whitehead, Gareth J. Conduit, Matthew D. Segall
Link / DOI: https://doi.org/10.4155/fdd-2020-0008